前言
近期,我们收到客户反馈,其部署在ARM64架构设备上的软件加密性能远未达预期。经GDB调试分析,症结在于所使用的OpenSSL库默认采用纯C语言实现的通用加密算法——该实现虽能保障跨平台兼容性,却无法充分发挥现代ARM处理器的硬件加速潜力。
自2014年ARMv8.1-A架构发布起,ARM便引入ARMv8 Crypto Extensions(加密扩展),为AES、SHA等常用加密算法提供硬件指令级支持,理论上可实现数倍性能提升。然而,客户在X86开发环境中进行交叉编译时,因未针对目标ARM架构优化编译配置,导致生成的OpenSSL库未能启用该关键硬件加速功能。
一、ARMv8加密扩展的技术原理与价值
ARMv8-A架构的加密扩展是一套专为密码学操作设计的指令集扩展。据技术文档显示,该扩展在向量寄存器文件基础上新增32条高级SIMD指令,可显著提升多种主流加密算法的执行效率,具体体现在:
AES指令集:全面支持AES加密与解密的所有轮操作,大幅减少软件实现中繁琐的查表及移位运算。
SHA指令集:为SHA-1、SHA-256(A32/A64指令集均支持)及SHA-512、SHA-3、SM3、SM4(仅A64指令集支持)提供硬件加速能力。
性能提升:官方数据表明,该扩展可使软件加密性能提升3至10倍,尤其适用于数据粒度较小、不便卸载至外部硬件加速器的加解密场景。
实际应用中,加密扩展的启用与否直接取决于编译配置。OpenSSL作为一款采用C语言开发、跨平台性能优异的开源密码学库,其架构设计支持针对不同CPU平台选用最优汇编代码实现。但在交叉编译场景下,编译器无法自动探测目标平台的硬件特性,需开发者手动显式指定。
二、交叉编译环境搭建与工具链配置
要在X86主机为ARM64目标设备编译OpenSSL,需先搭建完整的交叉编译工具链,核心步骤如下:
获取交叉编译工具链:本次选用gcc-linaro-7.4.1-2019.02-x86_64_aarch64-linux-gnu工具链,该版本稳定性强且兼容性广泛。
配置环境变量:将工具链的bin目录添加至系统PATH,同时明确指定交叉编译所需工具路径:
1 |
|
上述配置可确保后续编译过程中,系统调用的是适配aarch64(即ARM64)架构的编译器工具链。
三、OpenSSL 3.0的针对性编译配置与性能对比测试
编译配置是激活硬件加速的核心环节。本次以OpenSSL 3.0.9版本为测试对象,设计两种编译配置方案并开展对比测试。
3.1 启用ARMv8加密扩展的编译配置
通过./Configure脚本显式指定目标平台及架构特性,配置命令如下:
1 |
|
关键参数解读:
linux-aarch64:指定目标运行环境为Linux系统,架构为aarch64。
-march=armv8-a+crypto:核心优化参数,告知编译器生成适配ARMv8-A架构及加密扩展的代码,其中“+crypto”后缀是启用加密扩展的关键标识。
no-shared:编译生成静态库,便于后续测试部署及依赖管理。
3.2 禁用汇编优化的编译配置(作为对照)
为量化硬件加速的性能收益,我们编译了一个禁用所有汇编优化的版本作为基准对照组,配置命令如下:
1 |
|
其中“no-asm”参数会强制OpenSSL采用纯C语言实现所有算法,完全规避平台特定的汇编优化逻辑。
3.3 性能测试方法与结果分析
将两种配置编译生成的openssl可执行文件拷贝至ARM64目标设备(本次测试选用搭载Cortex-A76 CPU的树莓派),采用OpenSSL内置的speed命令开展性能基准测试,测试算法为aes-128-cbc,单组测试时长1秒。
1 | 带指令 |
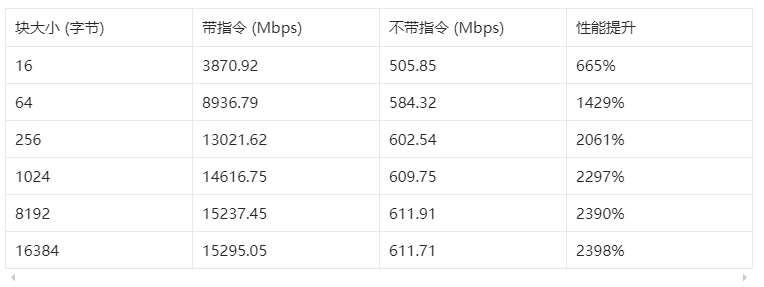
性能测试数据对比(单位:Mbps)
结果解读与核心洞察:
性能提升显著:启用加密扩展后,AES-128-CBC算法吞吐量实现7倍至25倍的跨越式提升,且数据块越大,加速效果越突出。该结果与ARM官方宣称的“3至10倍提升”相符甚至超出,充分验证了硬件指令集的性能优势。
提升规律清晰:小数据块(16字节)场景下,因函数调用等额外开销占比更高,加速比相对较低;而在1KB及以上的大数据块操作中,性能提升稳定在24倍左右,契合加密扩展指令高效处理大块数据的核心特性。
验证方法简洁:可通过speed命令输出的CPUINFO字段快速校验硬件加速是否启用——启用加密扩展的版本会显示“OPENSSL_armcap=0xbd”(代表检测到的ARM能力位图),而纯C实现版本则显示“CPUINFO: N/A”。
以上数据基于树莓派4B真实验证;
四、系统环境验证与安全考量
部署优化后的OpenSSL库前,需先确认目标硬件是否支持ARMv8加密扩展,可通过lscpu命令查看CPU特性:
1 |
|
其中“aes、pmull、sha1、sha2”等标志的存在,可直接证明该Cortex-A76处理器支持ARMv8加密扩展指令集。
五、总结与最佳实践建议
本次性能优化实践充分表明,为ARM64架构交叉编译OpenSSL时,显式启用ARMv8加密扩展是释放硬件性能潜力的核心举措。纯C语言实现虽能保障可移植性,但难以满足高性能加密场景的需求。
开发者最佳实践建议:
编译配置必选参数:务必指定“-march=armv8-a+crypto”,该参数是激活ARMv8加密扩展硬件加速的核心。
目标平台前置验证:交付软件前,需通过lscpu命令确认目标CPU支持aes、sha2等加密特性,并借助OpenSSL的speed工具开展性能基准测试,验证优化效果。
善用模块化设计:OpenSSL构建系统支持根据CPU架构自动匹配最优汇编代码,深入理解并利用该特性,可为不同目标平台生成极致优化的二进制文件。
遵循上述实践步骤,开发者可在X86开发环境中为ARM64服务器或嵌入式设备编译出高性能OpenSSL库,充分挖掘底层硬件的加密能力,最终交付性能卓越的安全软件产品。
OpenSSL构建系统可根据CPU架构自适应选择汇编优化代码,有效提升加密性能。
ARMv8 Crypto Extensions通过新增专用指令集,可使AES、SHA等加密算法性能提升3至10倍。
更多
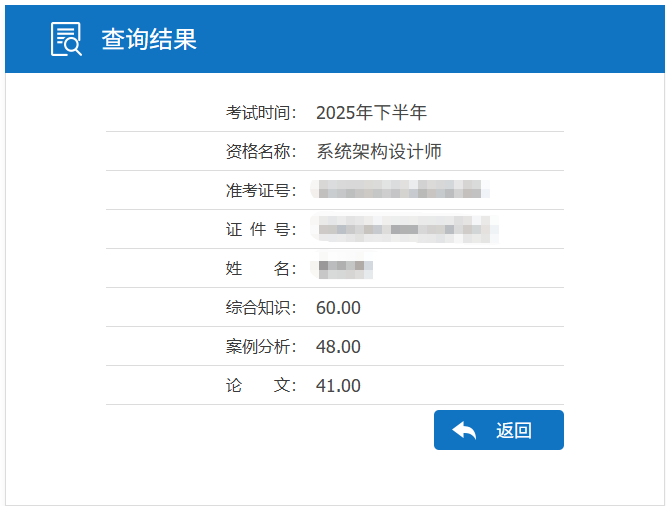
周五软考成绩公布,系统架构设计师师论文差 4 分未通过,知识水平仍需精进。但今年工作繁忙,备考精力远逊于去年系统分析师备考阶段,且备考中已强化了架构思维,整体不算遗憾。
12 月已持系统分析师证书申报集团高级工程师(评审通道无答辩,大概率通过),故此次架构师考试结果无关键影响。对我而言,知识落地应用才是核心。后续大概率会继续参考,计划转战高项、切入管理领域,坚持以考促学、学以致用。
行动,才不会被动!
欢迎关注个人公众号 微信 -> 搜索 -> fishmwei,沟通交流。

博客地址: https://fishmwei.github.io
掘金主页: https://juejin.cn/user/2084329776486919