前言
最近帮同事调试内核异步Crypto算法的性能测试,目标是榨干硬件的最大算力。但测试结果却让人意外:相同硬件下,64字节数据的内核态测试性能,居然只有用户态的1/10。
要知道这款硬件专门针对小字节场景做了优化,设计指标完全没发挥出来,这背后肯定不是硬件的问题,得从软件层面找原因。
代码剖析:原来测试逻辑“拖了后腿”
先看内核自带tcrypt测试程序的核心代码,问题其实藏在执行逻辑里:
1 | static inline int do_one_ahash_op(struct ahash_request *req, int ret) |
再看AEAD算法的并发测试逻辑:
1 | static int do_mult_aead_op(struct test_mb_aead_data *data, int enc, |
这两段代码暴露了关键问题:
- 基础测试逻辑是“下发一个、等待完成、再发下一个”,硬件并发数被限制为1,完全串行执行,根本发挥不出硬件的并发算力;
- AEAD算法虽支持num_mb批量下发,但本质还是“批量等待”,最大并发量被num_mb锁定,依然无法跑满硬件性能。
优化思路:参考用户态,实现“边下发边接收”
其实用户态的测试逻辑早就给出了标准答案——通过异步回调实现“只下发不等待”,让硬件持续处于高负载状态。我之前就把这个思路告诉了同事,可惜两三周过去,代码还没落地,最后还是得自己上手。
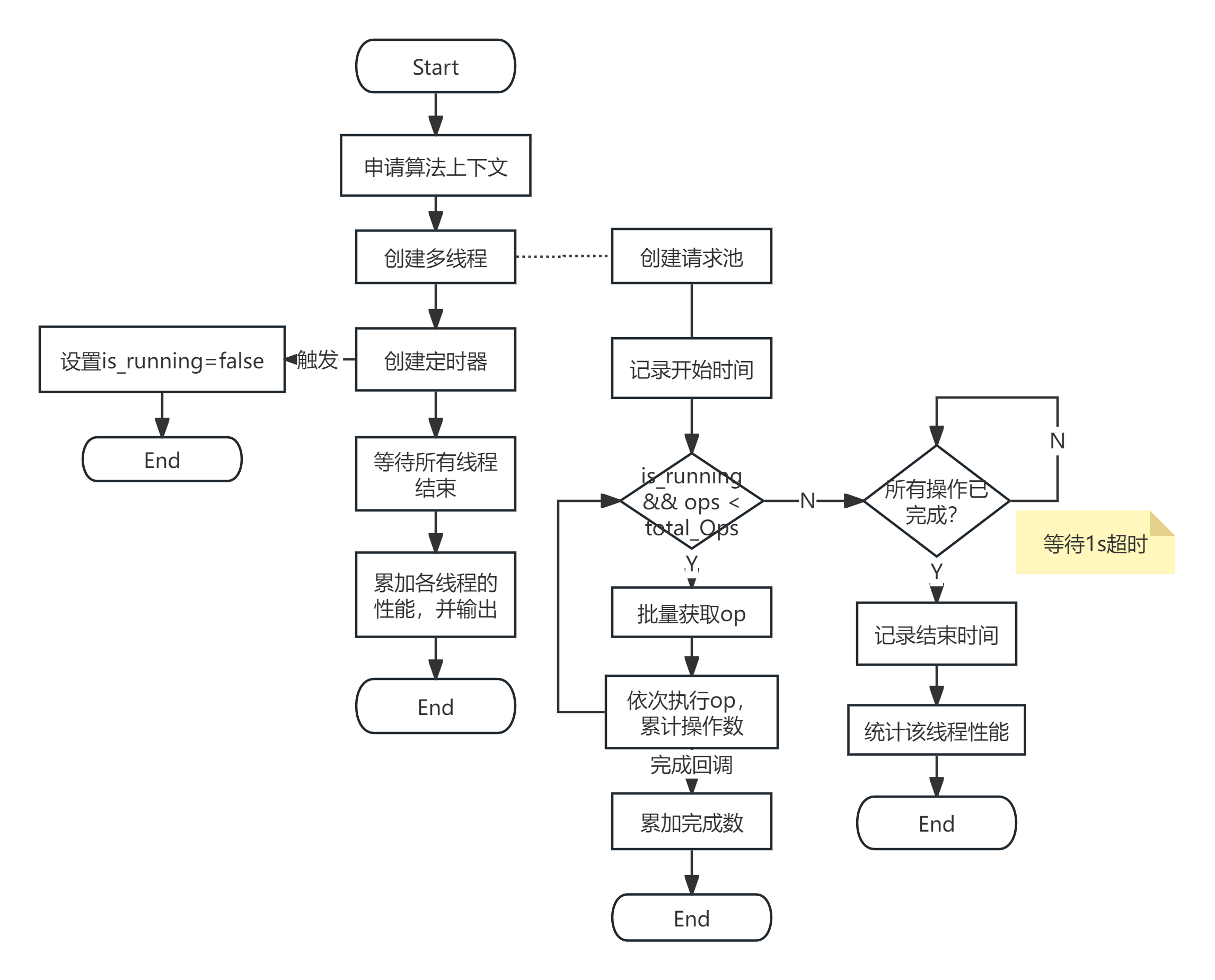
优化后的核心流程如下:
- 提前申请好算法上下文,避免运行时资源分配耗时;
- 创建多线程并发测试,每个线程独立统计性能;
- 预先创建命令请求池,提前分配好数据空间;
- 记录开始时间后,循环批量获取请求并下发;
- 通过重写request的callback函数,异步记录完成的请求数,无需主动等待;
- 用定时器设置测试停止标志,保证测试时长精准;
- 等待所有线程执行完毕,累加各线程性能数据,得到总性能。
完整的代码实现已上传至Gitee,可直接参考:https://gitee.com/fishmwei/blog_code/tree/master/linux-kernel/kspeed
优化结果:性能大幅提升,仍有优化空间
修改后的测试结果让人惊喜:
- 64字节场景:性能从用户态的1/10提升至1/3,小字节优化终于初步见效;
- 1024字节场景:性能完全追平用户态,说明修改后的逻辑已经能把硬件跑满。
不过64字节场景仍有差距,后续我又分析了算法实现的细节,找到了几个可以进一步优化的点,目前已经交给同事继续迭代。
性能测试不是“跑通就行”,而是要让硬件发挥出应有的实力。这次的踩坑经历也提醒我们:遇到性能不符预期时,不妨回头看看测试逻辑是否真的合理。
更多
周六一大早,就赶去赴系统架构师软考的“约”。考场里人头攒动,没想到还偶遇了上家公司的同事,简单聊了几句才知道,他也是主动报名的——大家都想着拿个证,算是给自己的专业能力一个官方认可,不得不说,现在职场人是真卷啊~
其实我上半年就报过一次名,可惜当时准备得太仓促,加上家里刚好有急事冲突,最后直接缺考了,干脆把希望寄托在下半年。可谁想到,下半年项目突然进入攻关期,连着两三个月忙得脚不沾地,备考只能见缝插针地翻几页书,根本没系统梳理。好不容易等到国庆有了空闲,10月份又撞上职级晋升的筹备,报的备考课都没来得及听完,复习计划再次被打乱。
直到10月底,才终于挤出时间突击补习了十几天。心里一边给自己打气“差不多准备好了”,一边又有点没底,但想想也只能硬着头皮上——成年人的备考,哪有“完全准备充分”这一说?工作、生活的琐事总会不断挤占时间,很多时候都是被事情推着往前走,尽力就好。
这次考试感觉有戏,但又不敢太笃定,一半期待一半忐忑,只能静静等着12月的成绩揭晓啦~
行动,才不会被动!
欢迎关注个人公众号 微信 -> 搜索 -> fishmwei,沟通交流。

博客地址: https://fishmwei.github.io
掘金主页: https://juejin.cn/user/2084329776486919