前言
平常每周都会有一些心得感悟,这些在大家工作中可能会有许多共性。我觉得花一些时间整理一下,跟粉丝读者们分享一下日常学习工作的想法和所得,这是一个很好的互动和文章分享的痛点。
这是第十四篇。
这周开始上班,工作的主要内容就是性能优化相关的。基于硬件加速,编写内核及用户接口,在主流的一些框架上做适配。做的还是服务支持级的内容。
DPDK原理
DPDK是INTEL公司开发的一款高性能的网络驱动组件,也是工作中需要涉及到的一个框架。DPDK为数据面应用程序提供一个简单方便的,完整的,快速的数据包处理解决方案,主要技术有用户态、轮询取代中断、零拷贝、网卡RSS、访存DirectIO等。
目前很多网络设备底层都是基于DPDK框架,直接从驱动层截取数据包,然后通过用户程序实现功能。
UIO(Linux Userspace I/O)
提供应用空间下驱动程序的支持,也就是说网卡驱动是运行在用户空间的,减下了报文在用户空间和应用空间的多次拷贝。DPDK就绕过了Linux内核的网络驱动模块,直接从硬件层面获取数据包到用户态程序,减少了频繁的系统调用和内存拷贝。显著的提高了数据的采集效率。
UIO技术将设备驱动分为用户空间驱动和内核空间驱动两部分,内核空间驱动主要负责设备资源分配、UIO设备注册以及小部分中断响应函数,驱动的大部分工作在用户空间的驱动程序下完成。
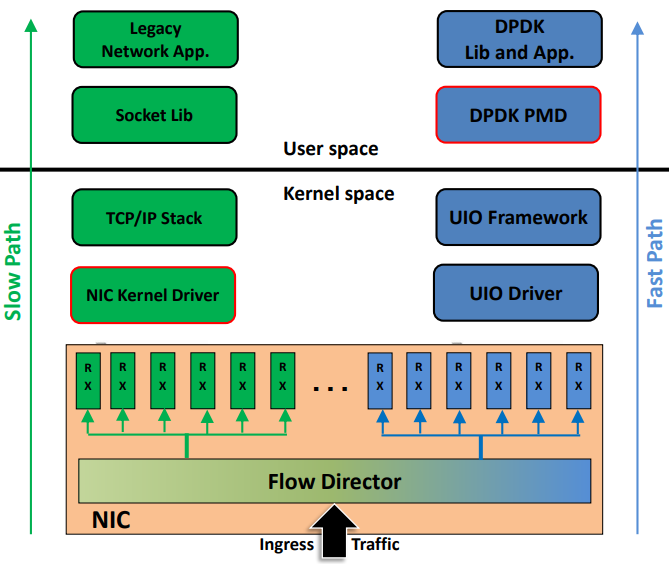
用户空间轮询模式(PMD)
传统中断模式: 传统Linux系统中,当网络设备检测到数据帧过来的时候,会使用DMA(直接内存访问)将帧发送到预先分配好的内核缓冲区里面,然后更新相应的接收描述符环,之后产生中断通知有数据帧过来。Linux系统会进行相应的响应,然后更新相应的描述符环,再将接收到的数据帧交给内核中的网络堆栈进行处理,网络堆栈处理完之后会将相应的数据拷贝到相应的套接字,从而数据就被复制到了用户空间,应用程序就可以使用这些数据了;
在发送的时候,一旦用户程序处理完了数据,会通过一个系统调用将数据写入到套接字,将数据从用户空间拷贝到内核空间的缓冲区,交由网络堆栈进行处理,网络堆栈根据需要对数据进行封装并调用网卡设备的驱动程序,网卡设备驱动程序会更新传输描述符环,然后向网卡设备告知有数据帧需要传输。网卡设备会将数据帧从内核中的缓冲区拷贝到自己的缓冲区中并发送到网络链路上,传送到链路上之后,网卡设备会通过一个中断告知成功发送,然后内核会释放相应的缓冲区。
由于linux系统是通过中断的方式告知CPU有数据包过来的,当网络的流量越来越大,linux系统会浪费越来越多的时间去处理中断,当流量速率达到10G的时候,linux系统可能会被中断淹没,浪费很多CPU资源。
DPDK用户空间的轮询模式驱动:用户空间驱动使得应用程序不需要经过linux内核就可以访问网络设备卡。网卡设备可以通过DMA方式将数据包传输到事先分配好的缓冲区,这个缓冲区位于用户空间,应用程序通过不断轮询的方式可以读取数据包并在原地址上直接处理,不需要中断,而且也省去了内核到应用层的数据包拷贝过程。
因此相对于linux系统传统中断方式,Intel DPDK避免了中断处理、上下文切换、系统调用、数据复制带来的性能上的消耗,大大提升了数据包的处理性能。同时由于Intel DPDK在用户空间就可以开发驱动,与传统的在内核中开发驱动相比,安全系数大大降低。因为内核层权限比较高,操作相对比较危险,可能因为小的代码bug就会导致系统崩溃,需要仔细的开发和广泛的测试。而在应用层则相反,比较安全,且在应用层调试代码要方便的多。
大页内存
Linux操作系统通过查找TLB来实现快速的虚拟地址到物理地址的转化。由于TLB是一块高速缓冲cache,容量比较小,容易发生没有命中。当没有命中的时候,会触发一个中断,然后会访问内存来刷新页表,这样会造成比较大的时延,降低性能。Linux操作系统的页大小只有4K,所以当应用程序占用的内存比较大的时候,会需要较多的页表,开销比较大,而且容易造成未命中。相比于linux系统的4KB页,Intel DPDK缓冲区管理库提供了Hugepage大页内存,大小有2MB和1GB页面两种,可以得到明显性能的提升,因为采用大页内存的话,可以需要更少的页,从而需要更少的TLB,这样就减少了虚拟页地址到物理页地址的转换时间。
简单的说,DPDK一次分配大段内存,然后自行管理这块内存。减少了内存缺页引起的中断处理,提高性能。
CPU亲和性
CPU的亲和性(CPU affinity),它是多核CPU发展的结果。随着核心的数量越来越多,为了提高程序工作的效率必须使用多线程。但是随着CPU的核心的数目的增长,Linux的核心间的调度和共享内存争用会严重影响性能。利用Intel DPDK的CPU affinity可以将各个线程绑定到不同的cpu,可以省去来回反复调度带来的性能上的消耗。 特别的,可以一定程度上减少临界资源的所操作,特定的业务只在指定CPU上执行的话,不会存在资源竞争的情况。
另外,多核机器上面,每个CPU核心本身都存在自己的缓存,缓冲区里存放着线程使用的信息。如果线程没有绑定CPU核,那么线程可能被Linux系统调度到其他的CPU上,这样的话,CPU的cache命中率就降低了。利用CPU的affinity技术,一旦线程绑定到某个CPU后,线程就会一直在指定的CPU上运行,操作系统不会将其调度到其他的CPU上,节省了调度的性能消耗,从而提升了程序执行的效率。
内存池和无锁环形缓存管理
此外Intel DPDK将库和API优化成了无锁,比如无锁队列,可以防止多线程程序发生死锁。然后对缓冲区等数据结构进行了cache对齐。如果没有cache对齐,则可能在内存访问的时候多读写一次内存和cache。
内存池缓存区的申请和释放采用的是生产者-消费者模式无锁缓存队列进行管理,避免队列中锁的开销,在缓存区的使用过程中提高了缓冲区申请释放的效率。
主要也是减少了临界资源的锁操作,提升性能。
网络存储优化
具体的没有深入了解。
更多
这周在新公司开始了新的工作,刚来嘛 就是先看看文档和代码。文档相对比较少,就一两个,稍微浏览了一遍,然后就开始干代码了。
用sourcecounter计算了一下,代码总共近5万行。
还是用老办法,也是笨办法,快速按文件扫一下代码,5万行需要花个四五天的时间,中间把跟业务无关的机制类的代码详细看看,做做笔记吧。业务相关的就扫描一下,记住一些关键的函数名,等扫描完一遍代码,再找几个入口函数串一下大的流程。这样很快就可以对软件整体架构有了具体的认识,最后就是把软件的整个框架稍微整理一下。接下去就是深入业务细节了,细节这个东西就会遇到比较多的问题了,可以先上网络搜一下,实在搞不清楚的都记录下来,找时间问问老员工。这样子后面就可以比较轻松的增删需求。从中也可以找找优化点啊。
在没有文档的情况下,一头栽进代码里,不求甚解,混个脸熟也好。只有这样才能快速成长,也比较容易对代码流程具象化。这个时间还是需要花的,代码也得认真看。这个就是刻意练习加一万小时定律,不要急躁,沉下心来,看到心里去。
上周末看了一个电视剧《大舜》,不论是虞舜还是大禹,他们治水也是这么个过程。都是走遍了大河的上下游,才能真正了解洪水,了解之后才能找到更好的破解之法。随着华夏的统一,对整个水系网络看的也更全面了,后面就自然而然的找到更好的解法。
从中看出,其实做事情的道理都是相同的。先有了足够的认知,才能有更好的解决办法。开头是比较难的,但是坚持下来结果还是不会辜负这份辛苦的。
在看代码的过程中,也可以看到很多设计模式的影子和原则,万事皆相通。做代码笔记的时候,很容易使用到类图来勾画各个结构体之间的关系,使用面向对象的思想读代码也很受益。
行动,才不会被动!
欢迎关注个人公众号 微信 -> 搜索 -> fishmwei,沟通交流。