前言
几个月前了吧,团队有人测试了一下通过netconf给list类型的节点添加2w条表项,发现随着表项数目的增加,后面创建新表项的时间几乎呈一个线性的增长。到最后,每增加一个配置,大概就要耗时8s左右的时间,很显然,这是一个比较严重的性能问题。另外,即使你修改其他模块的配置,这个耗时也要6s左右的时间。就是如果一个模块的配置量很大,还会影响到其他模块的处理,这个就更严重了。
分析
通过分析,耗时长的函数主要就是sr_modinfo_data_load、lyd_validate_modules、sr_modinfo_data_store。 其实很容易就可以看出来,在配置量巨大的情况下,保存的配置的数据量就更多,这样就导致加载/校验/保存的时间更长了。
这样看来,sysrepo的框架已经决定了它不适合大量配置的情形,动不动就上千万的配置就更不可能了。通过后期对代码的深入,我总结了几点sysrepo性能问题的根因:
- 内容是否更改是通过字符串比对来实现的(参考函数lyd_anydata_equal实现), 配置大的时候,生成的字符串很长,比对耗时
- 顶级模块相同的不同模块配置保存在同一个文件(顶级模块的文件), 很多下级模块其实是对一个顶级模块的argument,这些下级模块的配置并没有拆分到独立的文件,某一个模块数据量很大的时候,加载配置文件就很慢,还会影响其他的模块
- 每次修改保存都重新写入文件,我们知道IO是一个比较慢的操作,数据量越大那么时间就更长了
- 共享内存文件锁,只要有一个进程在读取大数据配置,锁就会占用,其他进程就挂在那儿了
- yang数据是一棵树,每一级其实都是一个双向链表,我们知道双向链表的查找效率是O(n),这个也导致在数据检索和修改的耗时长。
总的来说,框架的总体设计已经决定了sysrepo的瓶颈。综合看上面几个原因,也就只能通过拆分各个模块的数据,优化模块间相互依赖的问题了。
优化
针对我们项目的配置都在一个顶级模块下面,那么我就从次级模块进行了拆分, 顶级模块文件只保留其自身模块的数据,而次级模块文件保留顶级模块的部分数据和自身模块的数据。这样,就是顶级模块会有多个备份,每个有数据的次级模块几乎都会存一份顶级模块的数据。只能这样了,通过空间换时间吧。
对配置的操作,需要根据请求的配置,加载对应模块及其依赖模块的数据(用于校验),然后进行数据变更,相互依赖的配置还是会有影响的。
另外在处理逻辑上,需要在删除/替换顶级模块配置的时候,同时同步到所有次级模块,也就是需要加载其下的所有模块。为了正确性,这个是没有办法避免的。
嗯, sysrepo还提供了缓存的功能,在缓存的处理上和拆分下级模块是一样的,不同的是,之前缓存的是running数据库的整个数据森林,只有一份。 但之前数据文件会有多份,因为有多个顶级模块。这个也没有多复杂,就是缓存按模块来分,除了项目的顶级模块只存自身数据外,其他顶级模及其下级模块不进行拆分,平常不需要用到。
拆分的示意图,我简单手绘了一下:
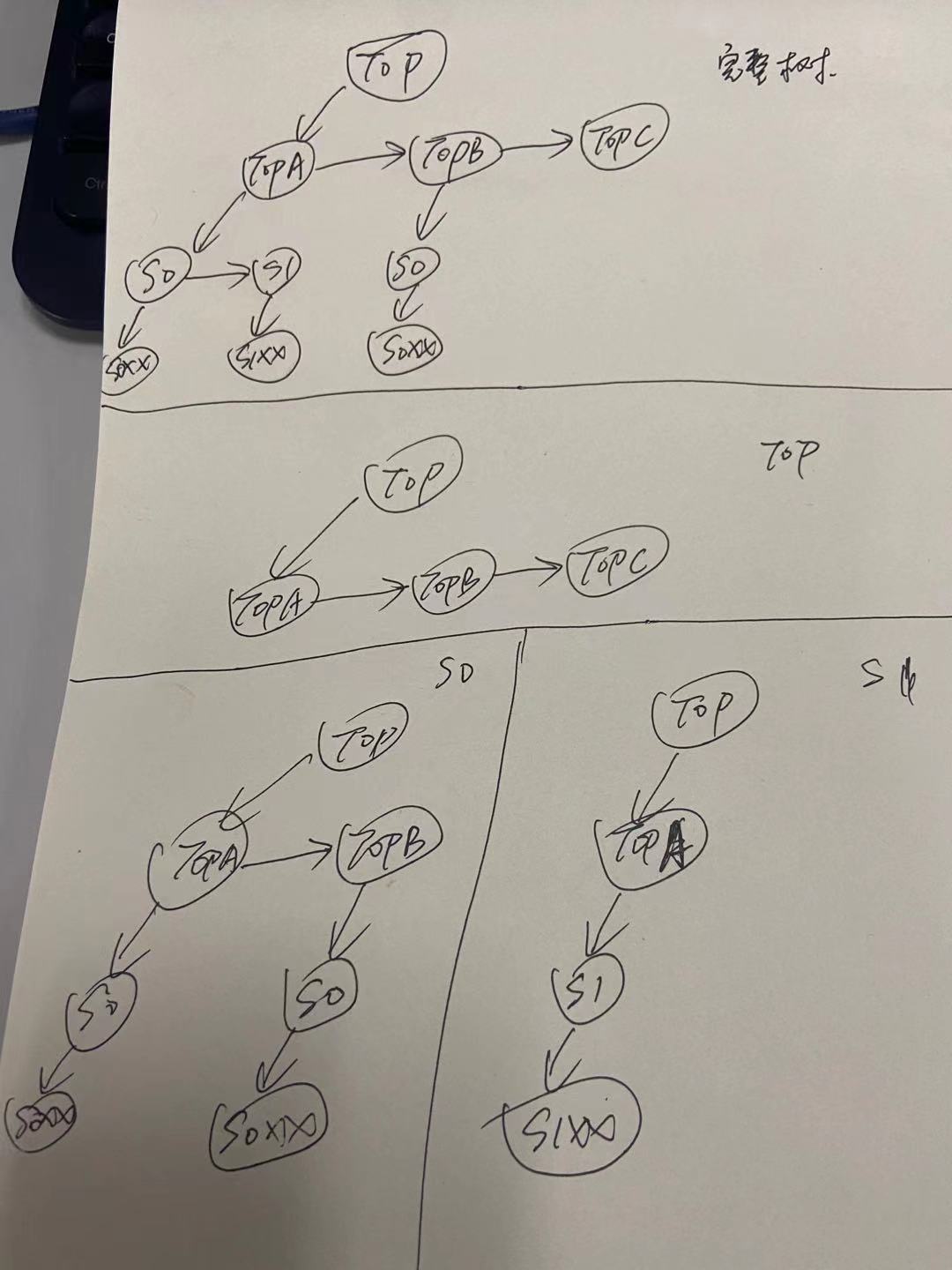
后话
sysrepo的优化前后耗时快一个半月了,sysrepo库总体代码量大概3w行,前面三周几乎都是在熟悉代码,后面按思路进行编码拆分,中间遇到很多问题,前后得有30个上下吧。昨天才把基本的逻辑调试完,今天小结一下。 还得设计一下测试用例,后面两周按照用例过一下,然后再优化一下代码。后面估计还有许多坑,加油吧!
这段时间,天天都很忙,在不停的调试问题,逢山开路,遇水搭桥。 国庆假期都贡献了2天免费加班了,精神高度集中,脑袋超负荷运转,真是有点儿疲惫不堪。终于快到尾声了,飒!!
行动,才不会被动!
欢迎关注个人公众号 微信 -> 搜索 -> fishmwei,沟通交流。