文件读写
文件创建、打开之后, 就是对其进行读写操作了。
系统调用层和虚拟文件系统层
文件系统的读写,其实就是调用系统函数 read 和 write。
read 和 write 的系统调用,在内核里面的定义, 具体的在read_write.c里面。
1 |
|
对于 read 来讲,里面调用 vfs_read->__vfs_read。对于 write 来讲,里面调用 vfs_write->__vfs_write。
这里通过fd获取到struct fd。 struct fd里面保存了 struct file 和 flags。
1 | struct fd { |
struct file里面有struct path和struct inode, struct path里面有 struct vfsmount 和struct dentry。
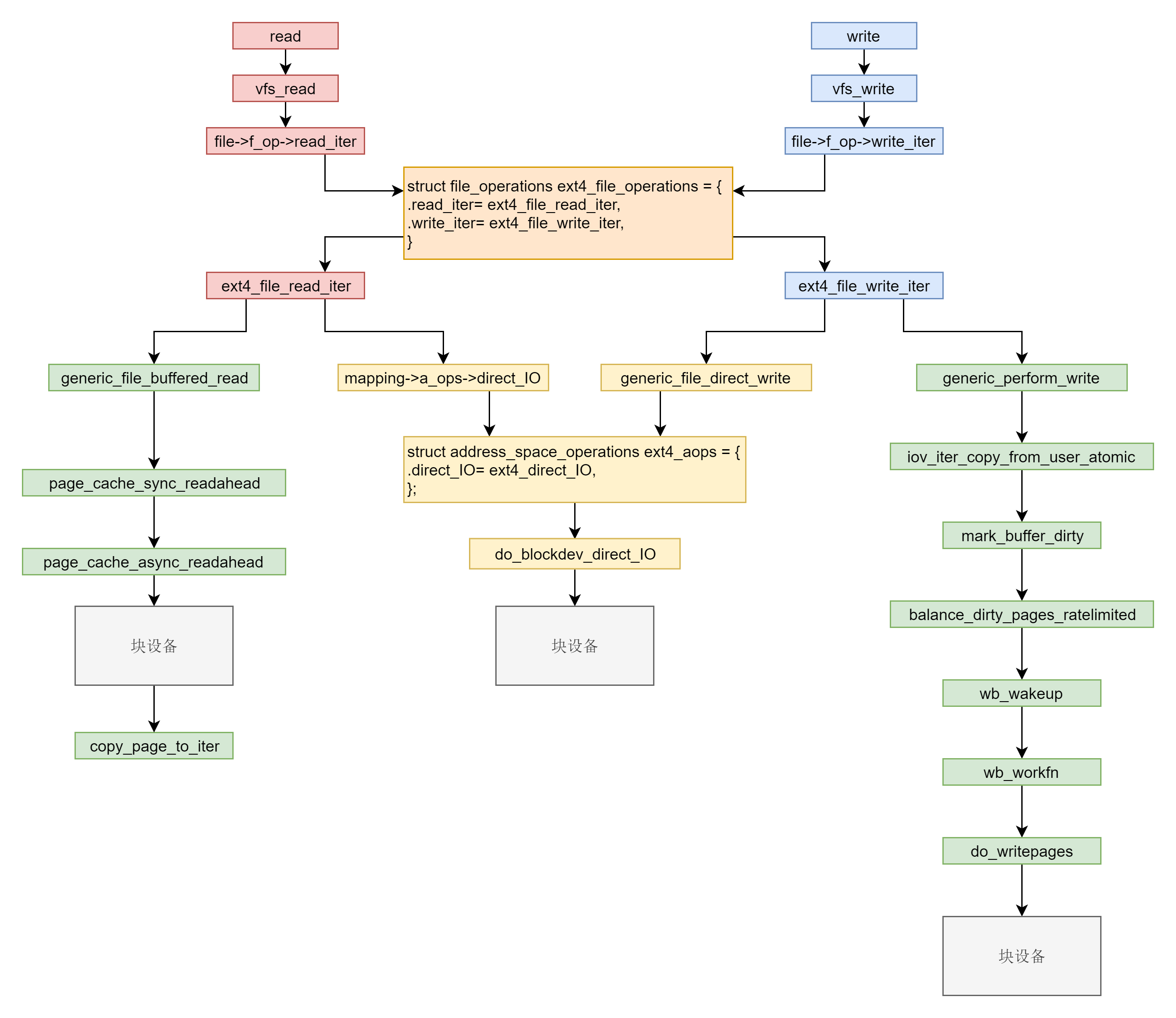
具体的读写, 最终调用到 file->f_op->read 和 file->f_op->write。
ext4 文件系统层
对于 ext4 文件系统来讲,内核定义了一个 ext4_file_operations。里面就是对ext4文件系统的文件操作的回调函数。
1 |
|
这里有两种模式的读写操作, 一种是读缓存,缓存没有再读硬盘, 一种是直接读硬盘。
缓存其实就是内存中的一块空间。因为内存比硬盘快得多,Linux 为了改进性能,有时候会选择不直接操作硬盘,而是读写都在内存中,然后批量读取或者写入硬盘。一旦能够命中内存,读写效率就会大幅度提高。
根据是否使用内存做缓存,我们可以把文件的 I/O 操作分为两种类型。
第一种类型是缓存 I/O。大多数文件系统的默认 I/O 操作都是缓存 I/O。对于读操作来讲,操作系统会先检查,内核的缓冲区有没有需要的数据。如果已经缓存了,那就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说,写操作就已经完成。至于什么时候再写到磁盘中由操作系统决定,除非显式地调用了 sync 同步命令。
第二种类型是直接 IO,就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和用户程序之间数据复制。
具体的就是看你参数里面有没有设置IOCB_DIRECT了。设置的话就直接从硬盘进行读写,否则会先处理缓存。由于文件系统是块设备,所以最终调用的是 blockdev 相关的函数。
带缓存的写入操作
在__generic_file_write_iter函数里面,根据flags是否设置IOCB_DIRECT就分别处理里, 最后都调用了带缓存写入的函数generic_perform_write。
1 |
|
这个函数是一个do…while循环,具体就是做以下的工作:
- 对于每一页,先调用 address_space 的 write_begin 做一些准备;
- 调用 iov_iter_copy_from_user_atomic,将写入的内容从用户态拷贝到内核态的页中;
- 调用 address_space 的 write_end 完成写操作;
- 调用 balance_dirty_pages_ratelimited,看脏页是否太多,需要写回硬盘。所谓脏页,就是写入到缓存,但是还没有写入到硬盘的页面。
第一步ext4_write_begin
ext4 是一种日志文件系统,日志文件系统比非日志文件系统多了一个 Journal 区域。文件在 ext4 中分两部分存储,一部分是文件的元数据,另一部分是数据。元数据和数据的操作日志 Journal 也是分开管理的。他有3个模式,需要在挂载文件系统的时候设置,也可以后续通过tune2fs命令设置,具体的就没去操作了。
- 日志(Journal)模式 这种模式在将数据写入文件系统前,必须等待元数据和数据的日志已经落盘才能发挥作用。这样性能比较差,但是最安全。
- order 模式 这个模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式。
- writeback 不记录数据的日志,仅记录元数据的日志,并且不保证数据比元数据先落盘。这个性能最好,但是最不安全。
在 ext4_write_begin,我们能看到对于 ext4_journal_start 的调用,就是在做日志相关的工作。在 ext4_write_begin 中,还做了另外一件重要的事情,就是调用 grab_cache_page_write_begin,来得到应该写入的缓存页。
在内核中,缓存以页为单位放在内存里面,那我们如何知道,一个文件的哪些数据已经被放到缓存中了呢?每一个打开的文件都有一个 struct file 结构,每个 struct file 结构都有一个 struct address_space 用于关联文件和内存,就是在这个结构里面,有一棵树,用于保存所有与这个文件相关的的缓存页。我们查找的时候,往往需要根据文件中的偏移量找出相应的页面,而基数树 radix tree 这种数据结构能够快速根据一个长整型查找到其相应的对象,因而这里缓存页就放在 radix 基数树里面。如果找不到,那就创建一个缓存页。
第二步,调用 iov_iter_copy_from_user_atomic。先将分配好的页面调用 kmap_atomic 映射到内核里面的一个虚拟地址,然后将用户态的数据拷贝到内核态的页面的虚拟地址中,调用 kunmap_atomic 把内核里面的映射删除。为什么要拷贝呢,因为这是一个系统调用, 需要在内核安全的地方进行操作,当然需要在内核空间了。
第三步,调用 ext4_write_end 完成写入。这里面会调用 ext4_journal_stop 完成日志的写入,会调用 block_write_end->__block_commit_write->mark_buffer_dirty,将修改过的缓存标记为脏页。可以看出,其实所谓的完成写入,并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页。
第四步,调用 balance_dirty_pages_ratelimited,是回写脏页的一个很好的时机。
在 balance_dirty_pages_ratelimited 里面,发现脏页的数目超过了规定的数目,就调用 balance_dirty_pages->wb_start_background_writeback,启动一个背后线程开始回写。这里需要葬爷数目超过规定的数目才进行写。如果永远不超过,就需要另外一个机制了,定时回写。这里不详细讲了。
当然,除了被动回写, 用户也可以主动调用sync, 立马触发回写,同步脏页。
带缓存的读操作
对应的是函数 generic_file_buffered_read。
在 generic_file_buffered_read 函数中,我们需要先找到 page cache 里面是否有缓存页。如果没有找到,不但读取这一页,还要进行预读,这需要在 page_cache_sync_readahead 函数中实现。预读完了以后,再试一把查找缓存页,应该能找到了。如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用 page_cache_async_readahead 发起一个异步预读。最后,copy_page_to_iter 会将内容从内核缓存页拷贝到用户内存空间。
基数树
这边,struct address_space缓存页管理使用了基数树这种数据结构,radix树是一种针对稀疏的长整型数据查找,可以快速节省空间的完成映射。可以基于长整型快速路由到叶子节点,叶子节点保存具体的数据。具体实现见radix-tree.c文件。
行动,才不会被动!
欢迎关注个人公众号 微信 -> 搜索 -> fishmwei,沟通交流。