thread_create线程创建
线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。pthread_create 不是一个系统调用,是 Glibc 库的一个函数。
用户态创建线程
创建线程首先就是要设置线程的参数。
1 | typedef struct |
就像在内核里一样,每一个进程或者线程都有一个 task_struct 结构,在用户态也有一个用于维护线程的结构,就是这个 pthread 结构。
然后就是创建一个线程栈。获取设置的栈大小,申请一段后面添加guard_size大小的空间,作为栈空间,当访问到后面guard_size的空间时报错。栈空间在线程退出后加入到缓存中get_cached_stack,新建线程首先会从缓存中获取适合的空间,否则新建。保存线程的pthread结构到栈空间里面,并且获取guard空间的大小,setup_stack_prot设置其为受保护的。然后就是初始化pthread内对应的值。最后将线程栈添加到stack_used 链表。也就是这个栈正被使用;另一个是 stack_cache,就是上面说的,一旦线程结束,先缓存起来,不释放,等有其他的线程创建的时候,给其他的线程用。线程栈的管理就是这2个链表来管理的。这个就是用户态栈的创建与管理。
内核态创建任务
继续上面的逻辑,然后是调用clone系统调用。
如果在进程的主线程里面调用其他系统调用,当前用户态的栈是指向整个进程的栈,栈顶指针也是指向进程的栈,指令指针也是指向进程的主线程的代码。此时此刻执行到这里,调用 clone 的时候,用户态的栈、栈顶指针、指令指针和其他系统调用一样,都是指向主线程的。
但是对于线程来说,这些都要变。因为我们希望当 clone 这个系统调用成功的时候,除了内核里面有这个线程对应的 task_struct,当系统调用返回到用户态的时候,用户态的栈应该是线程的栈,栈顶指针应该指向线程的栈,指令指针应该指向线程将要执行的那个函数。所以这些都需要我们自己做,将线程要执行的函数的参数和指令的位置都压到栈里面,当从内核返回,从栈里弹出来的时候,就从这个函数开始,带着这些参数执行下去。
资源赋值/设置
clone最终是调用到了do_fork函数。由于创建线程时,设置了clone_flags。所以在具体的流程中,资源不再是创建拷贝一份数据,而是对应的用户数/引用加一,内存指向原本的内存。
- files_struct 引用计数加一
- fs_struct 的用户数加一
- sighand_struct 引用计数加一
- mm直接指向了原来的 mm_struct
亲缘关系设置
使用了 CLONE_THREAD 标识位之后,使得亲缘关系有了一定的变化。如果是新进程,那这个进程的 group_leader 就是它自己,tgid 是它自己的 pid,这就完全重打锣鼓另开张了,自己是线程组的头。如果是新线程,group_leader 是当前进程的,group_leader,tgid 是当前进程的 tgid,也就是当前进程的 pid,这个时候还是拜原来进程为老大。如果是新进程,新进程的 real_parent 是当前的进程,在进程树里面又见一辈人;如果是新线程,线程的 real_parent 是当前的进程的 real_parent,其实是平辈的。
信号的处理
每个 task_struct,都会有这样一个成员变量,struct sigpending pending。这就是一个信号列表。如果这个 task_struct 是一个线程,这里面的信号就是发给这个线程的;如果这个 task_struct 是一个进程,这里面的信号是发给主线程的。整个进程里的所有线程共享一个 shared_pending,这也是一个信号列表,是发给整个进程的,哪个线程处理都一样。 子线程自己是没有独立的信号处理的?
用户态执行线程
clone系统调用返回后,会调用start_thread函数,里面调用传入的线程函数。在用户的函数执行完毕之后,会释放这个线程相关的数据。例如,线程本地数据 thread_local variables,线程数目也减一。如果这是最后一个线程了,就直接退出进程,另外 __free_tcb 用于释放 pthread。
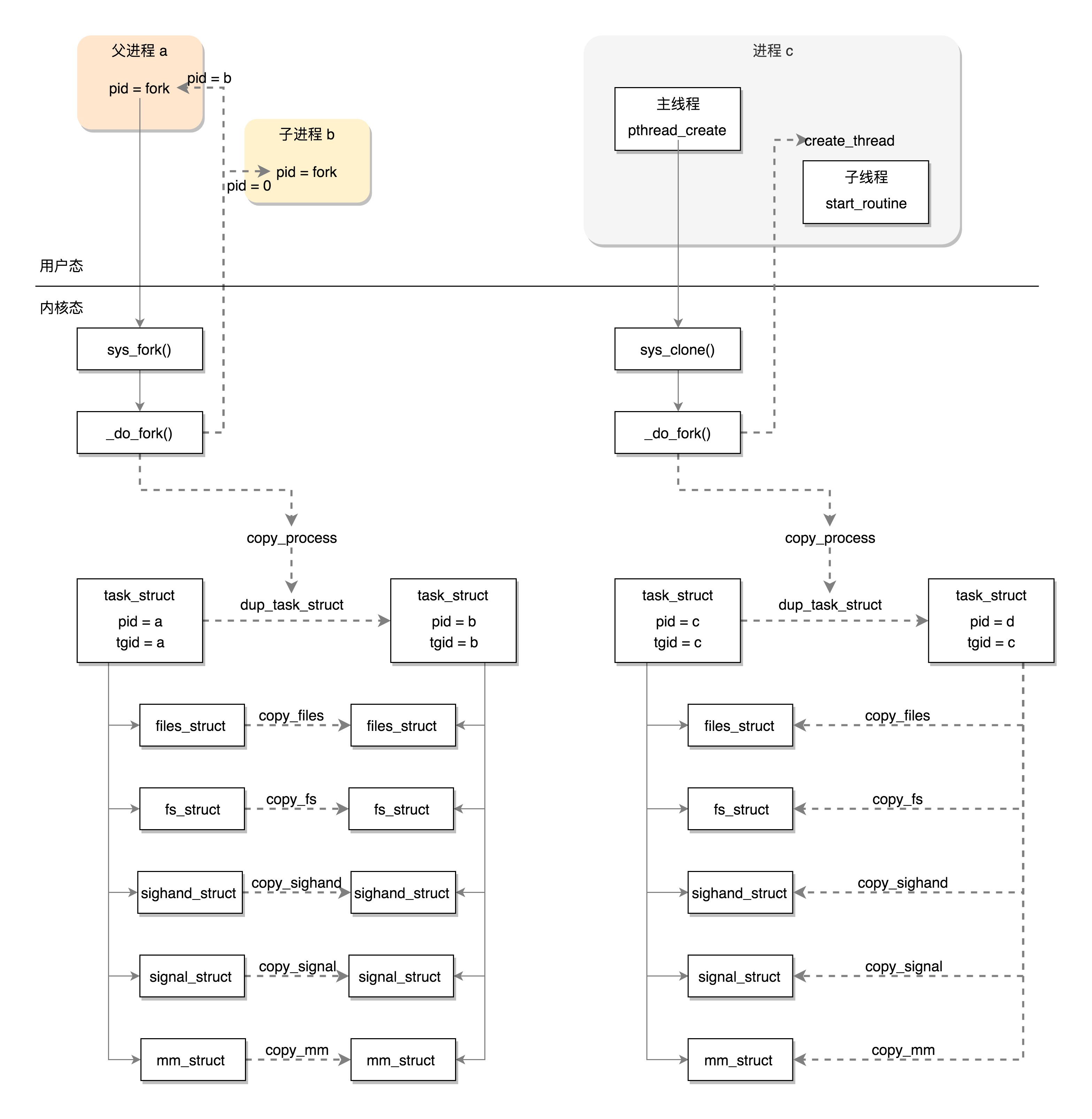
fork和clone的区别, fork对资源的复制是深拷贝, 全部重新申请一份新的, 拷贝内容。 clone呢,只是增加引用计数,浅拷贝,共享已有的资源, 线程共享进程的数据结构。五大结构:files_struct、fs_struct、sighand_struct、signal_struct、mm_struct。
行动,才不会被动!
欢迎关注个人公众号 微信 -> 搜索 -> fishmwei,沟通交流。